I created a solution for linear interpolation in Power Query. Optimal? Definitely not but it works!
Requirement
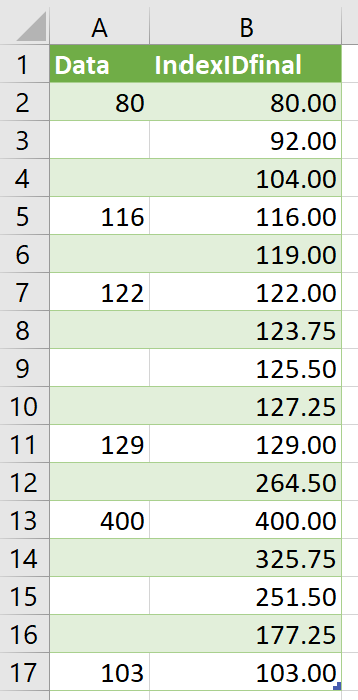
Numbers are separated by blanks. Fill in the blanks with evenly spaced numbers.
Ex: 2 blanks between 80 and 116, a difference of 36. End result = 80, 92, 104, 116.

End result should look like this:
Files: excel & pbix
Solution
WARNING: I haven’t tested this on a large dataset. It could be incredibly slow. Please test carefully.
I’ve split the solution into 5 queries.
- Table1 I added four helper columns
- Table1GroupBy group by with two aggregated columns plus helper column
- Merge1 pull together info from both queries above plus additional steps
- Merge1GroupBy ID that works even if there’s repeat groups w same details
- Merge2 final merge and helper columns
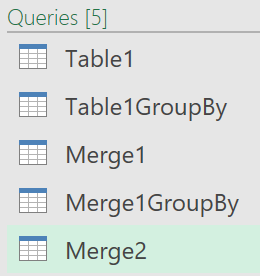
query1 Table1
Add columns
I created these 4 new columns:
- Index a counter
- Data – Copy Down copy of Data, numbers filled down
- Data – Copy Up copy of Data, numbers filled up
- Diff difference between Data – Copy Up & Data – Copy Down
Full M code query1 Table1:
let
Source = Excel.Workbook(File.Contents("C:\PBI local files\0023 Linear Interpolation\Excel Linear Interpolation start data.xlsx"), null, true),
Table1_Table = Source{[Item="Table1",Kind="Table"]}[Data],
#"Changed Type" = Table.TransformColumnTypes(Table1_Table,{{"Data", Int64.Type}}),
#"Added Index" = Table.AddIndexColumn(#"Changed Type", "Index", 1, 1, Int64.Type),
#"Duplicated Column" = Table.DuplicateColumn(#"Added Index", "Data", "Data - Copy Down"),
#"Filled Down" = Table.FillDown(#"Duplicated Column",{"Data - Copy Down"}),
#"Duplicated Column1" = Table.DuplicateColumn(#"Filled Down", "Data", "Data - Copy Up"),
#"Filled Up" = Table.FillUp(#"Duplicated Column1",{"Data - Copy Up"}),
Difference = Table.AddColumn(#"Filled Up", "Diff", each [#"Data - Copy Up"]-[#"Data - Copy Down"])
in
Difference
query2 Table1GroupBy
GroupBy
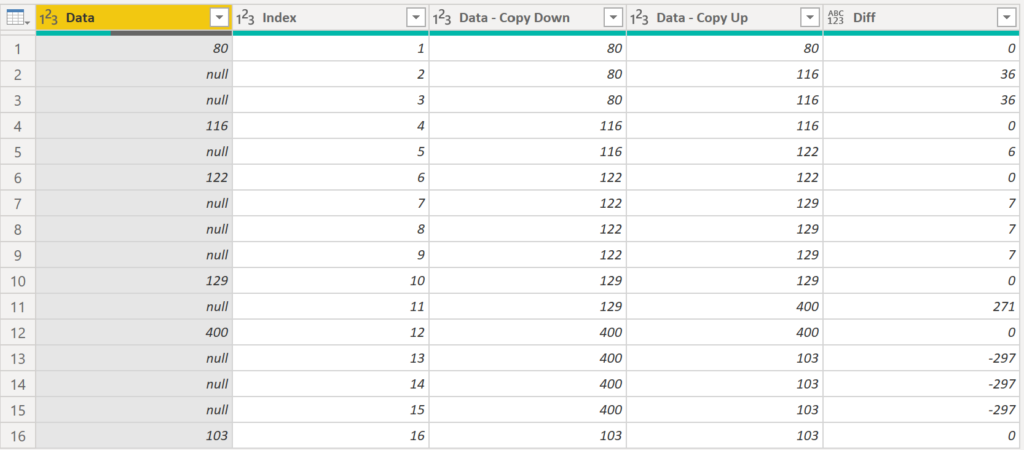
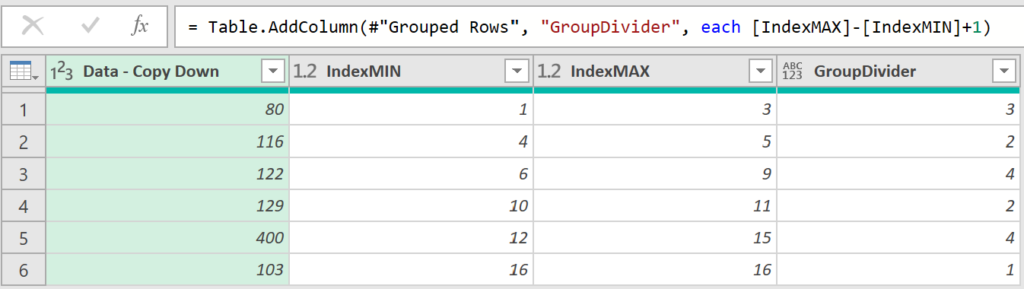
Group By on Data – Copy Down to get column Index min & max values.
Why? I need to count steps between numbers in original column Data.
Lower part of pic below we see the Group By. Upper part is the output.
Add Column: count steps
Added GroupDivider column to count steps between numbers.
Full M code query2 Table1GroupBy:
let
Source = Excel.Workbook(File.Contents("C:\PBI local files\0023 Linear Interpolation\Excel Linear Interpolation start data.xlsx"), null, true),
Table1_Table = Source{[Item="Table1",Kind="Table"]}[Data],
#"Changed Type" = Table.TransformColumnTypes(Table1_Table,{{"Data", Int64.Type}}),
#"Added Index" = Table.AddIndexColumn(#"Changed Type", "Index", 1, 1, Int64.Type),
#"Duplicated Column" = Table.DuplicateColumn(#"Added Index", "Data", "Data - Copy Down"),
#"Filled Down" = Table.FillDown(#"Duplicated Column",{"Data - Copy Down"}),
#"Duplicated Column1" = Table.DuplicateColumn(#"Filled Down", "Data", "Data - Copy Up"),
#"Filled Up" = Table.FillUp(#"Duplicated Column1",{"Data - Copy Up"}),
Difference = Table.AddColumn(#"Filled Up", "Diff", each [#"Data - Copy Up"]-[#"Data - Copy Down"])
in
Difference
query3 Merge1
Combined parts from query1 Table1 & query2 Table1GroupBy .
Merge: Table.NestedJoin
= Table.NestedJoin(Table1, {"Data - Copy Down"}, Table1GroupBy, {"Data - Copy Down"}, "Table1GroupBy", JoinKind.LeftOuter)
Merge produced M code above (syntax from Microsoft). Output is this:
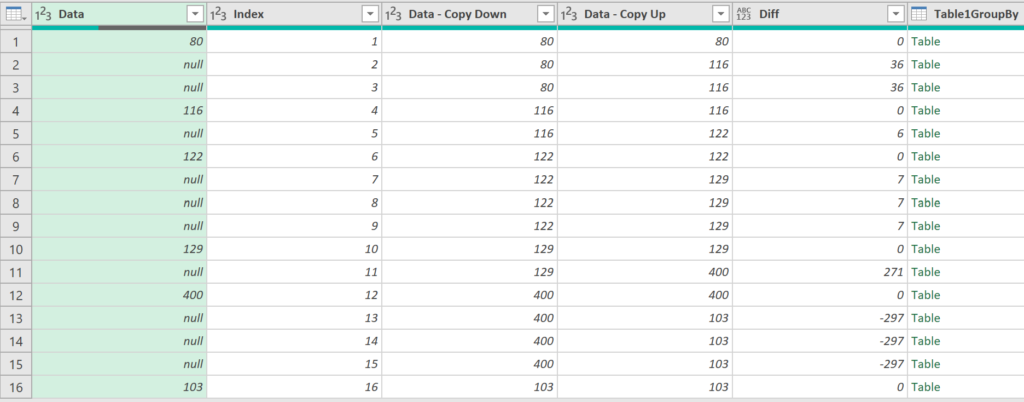
Left 5 columns from query1 Table1. Column Table1Groupby has nested tables (query2 columns).
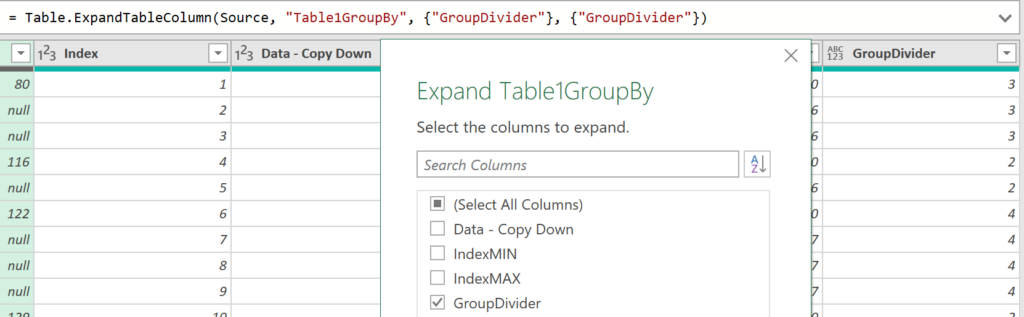
Expand: Table.ExpandTableColumn
I only want column GroupDivider from the nested table so we expand it:
Full M code query3 Merge1:
let
//MERGE TABLE1 & TABLE1GROUPBY
Source = Table.NestedJoin(Table1, {"Data - Copy Down"}, Table1GroupBy, {"Data - Copy Down"}, "Table1GroupBy", JoinKind.LeftOuter),
//EXPANDCOLUMN TO GET COLUMN GROUPDIVIDER
#"Expanded Table1GroupBy" = Table.ExpandTableColumn(Source, "Table1GroupBy", {"GroupDivider"}, {"GroupDivider"}),
//LIST CREATED TO GET PREVIOUS INDEX VALUE
#"Added Custom" = Table.AddColumn(#"Expanded Table1GroupBy", "Custom", each List.Range(Source[Index],[Index]-2, 1)),
//EXTRACT LIST VALUES
#"Extracted Values" = Table.TransformColumns(#"Added Custom", {"Custom", each Text.Combine(List.Transform(_, Text.From)), type text}),
//RENAME COLUMN: CUSTOM TO PREVINDEX
#"Renamed Columns" = Table.RenameColumns(#"Extracted Values",{{"Custom", "PrevIndex"}}),
//CONVERT EXTRACTED LIST VALUE TO NUMBER
#"Added Custom1" = Table.AddColumn(#"Renamed Columns", "Custom", each try Number.From([PrevIndex]) +0 otherwise 0),
//REMOVE COLUMN
#"Removed Columns" = Table.RemoveColumns(#"Added Custom1",{"PrevIndex"}),
//RENAMED CONVERTED TO NUMBER LIST VALUES TO PREVINDEXV2
#"Renamed Columns1" = Table.RenameColumns(#"Removed Columns",{{"Custom", "PrevIndexv2"}}),
//CREATE ID KEY TO BE USED FOR GROUPBY I THINK PROBLEM IS HERE! I NEED A STRONGER KEY IN CASE THERE ARE DUPLICATE START/STOP COMBOS WITH SAME VALUES!!!!!
//CAN'T SIMPLY USE INDEX AS THEN EVERY ROW IS UNIQUE
#"Added Custom2_ID_FIX_HERE" = Table.AddColumn(#"Renamed Columns1", "ID", each Text.From([#"Data - Copy Down"])&"_"&Text.From([#"Data - Copy Up"]))
in
#"Added Custom2_ID_FIX_HERE"
query4 Merge1GroupBy
I realized a major flaw in my original solution. What if a dataset has repeats?
My small sample has one pair for each 2 number combo. A dataset could have repeats. So I can’t use the concatenated pairs as a key (eg “80_116”). Solution? I did a group by on ID with minimum on Index column.
Group By
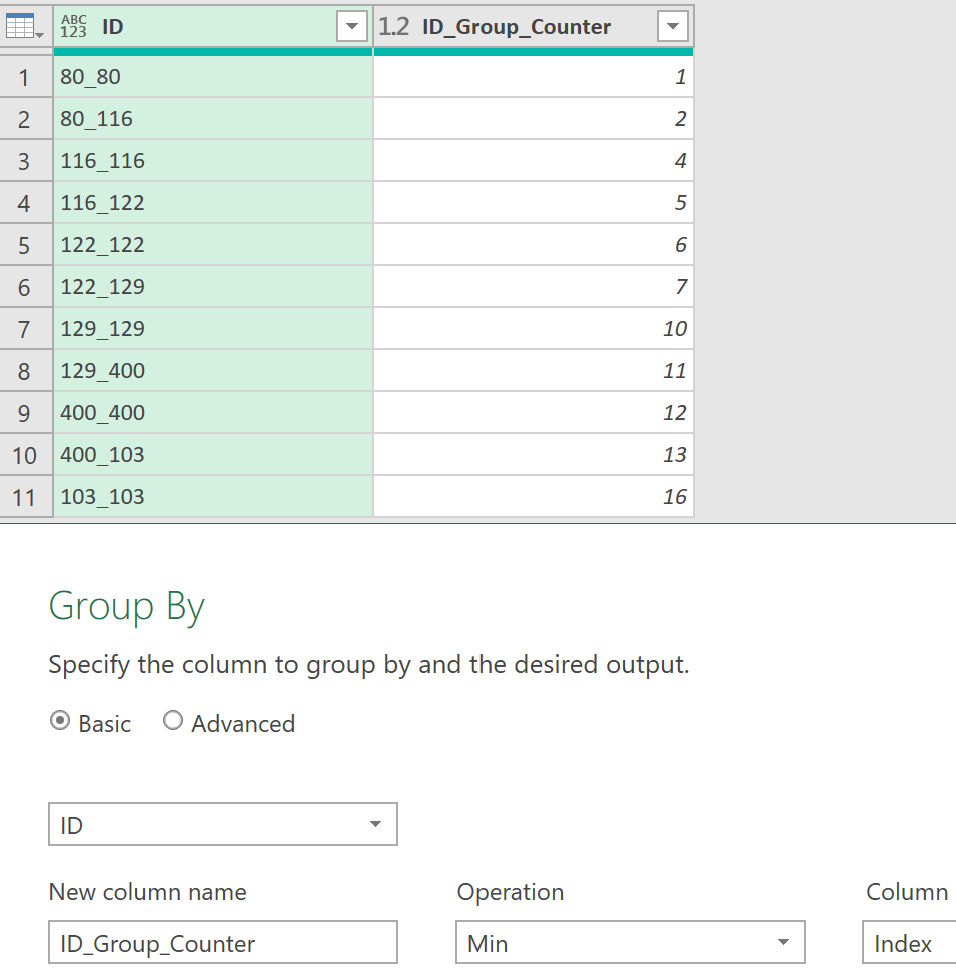
Add Column
I added a column to concatenate them to ensure uniqueness. There could be another “80_116” combo but the index number added to it would make it unique.
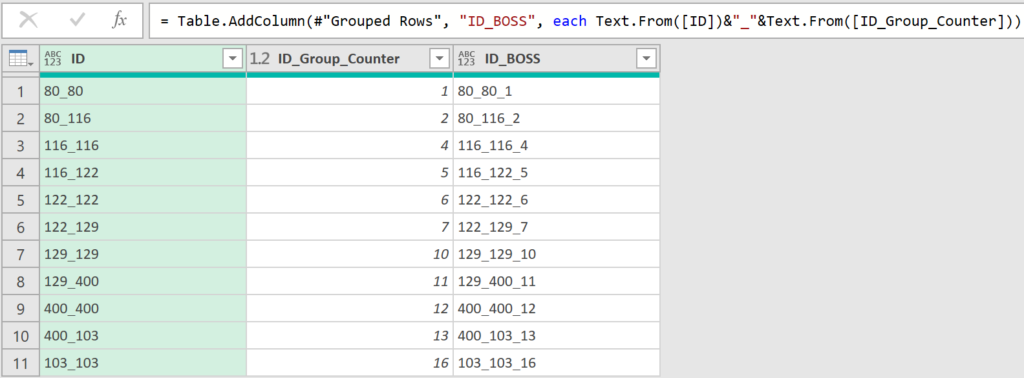
It seems that M won’t let me concatenate text without function Text.From
= Table.AddColumn(#"Grouped Rows", "ID_BOSS", each Text.From([ID])&"_"&Text.From([ID_Group_Counter]))
Full M code query4 Merge1GroupBy:
let
Source = Merge1,
#"Grouped Rows" = Table.Group(Source, {"ID"}, {{"ID_Group_Counter", each List.Min([Index]), type number}}),
#"Added Custom" = Table.AddColumn(#"Grouped Rows", "ID_BOSS", each Text.From([ID])&"_"&Text.From([ID_Group_Counter]))
in
#"Added Custom"
query5 Merge2
I need to merge fields from query4 and query5 and do several final steps.
Merge: Table.NestedJoin
The same merge/join type as in query3.
= Table.NestedJoin(Merge1, {"ID"}, Merge1GroupBy, {"ID"}, "Merge1GroupBy", JoinKind.LeftOuter)
Expand: Table.ExpandTableColumn
Similar to query3 I expanded the nested table to get column “ID_BOSS”.
Grouped Rows: Table.Group
Group By on key ID_BOSS with All Rows to create a nested Table. Left click white space to the right of any Table to see the rows inside.
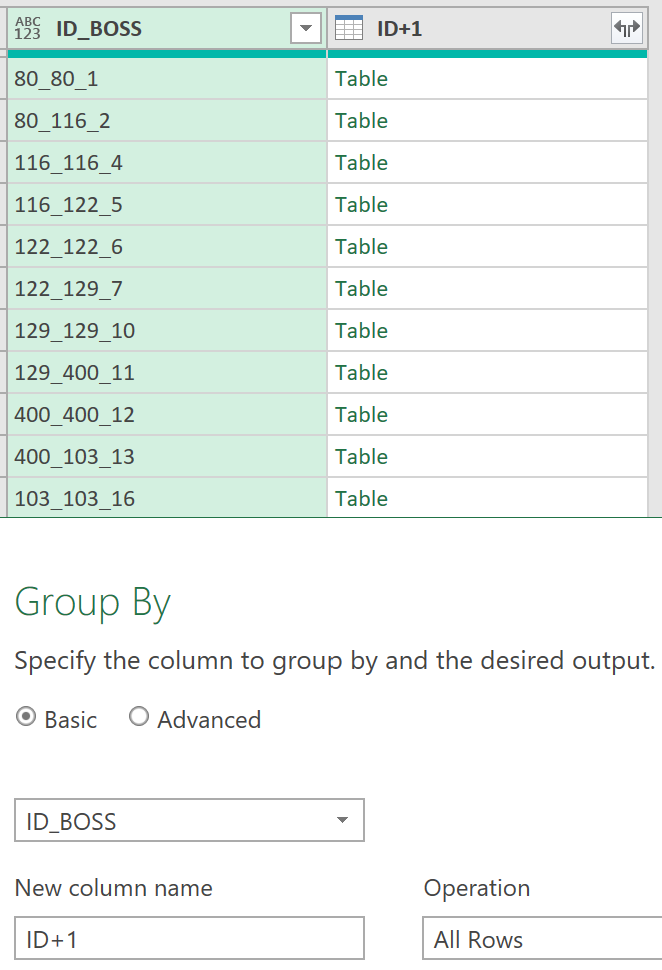
Add Column: Table.AddColumn
Why did I need column Partitioned with a 2nd nested table? To create a group counter inside each nested table!
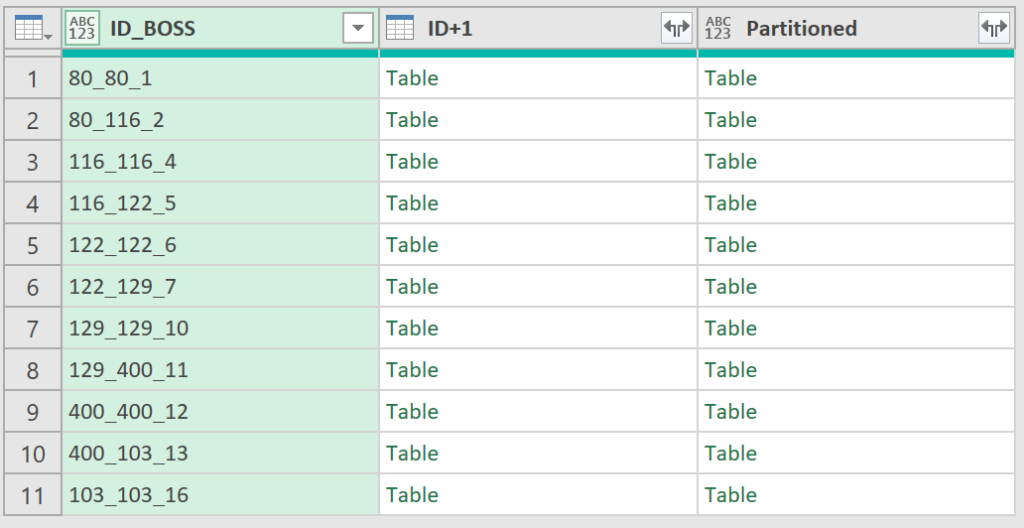
= Table.AddColumn(#"Grouped Rows", "Partitioned", each Table.AddIndexColumn([#"ID+1"], "IndexID+1", 1, 1))
Click white area to the right of Table in column Partitioned to see values. Column IndexID+1 has the group counter.
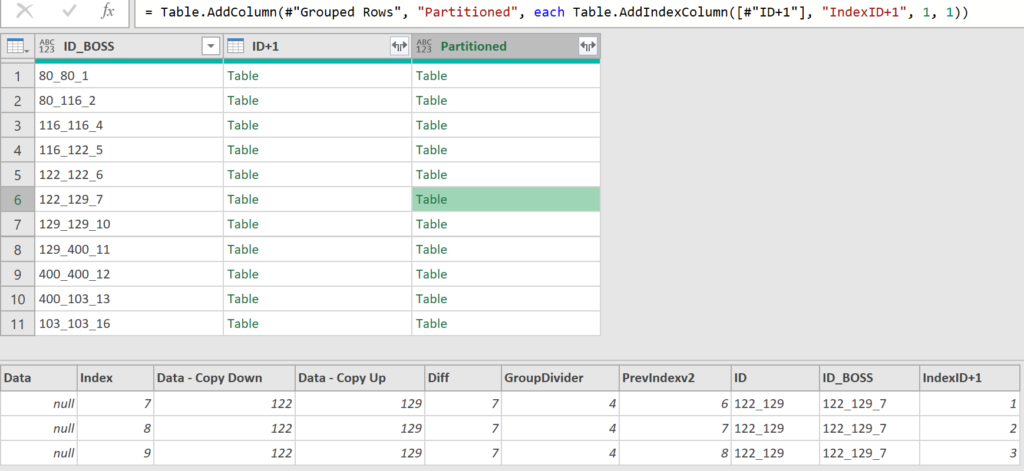
Expand: Table.ExpandTableColumn
Expand column Partitioned back to rows. Group counter resets for each group.
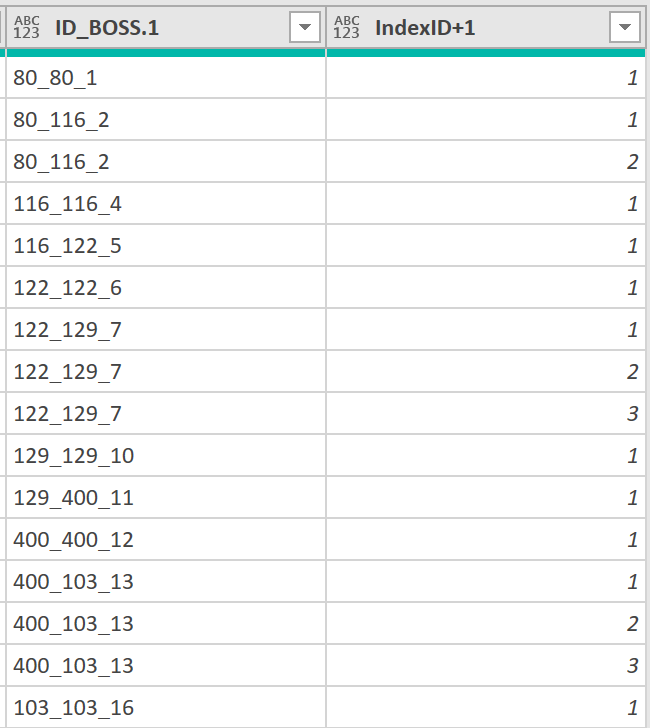
And now only a couple more steps.
Add Column: Table.AddColumn
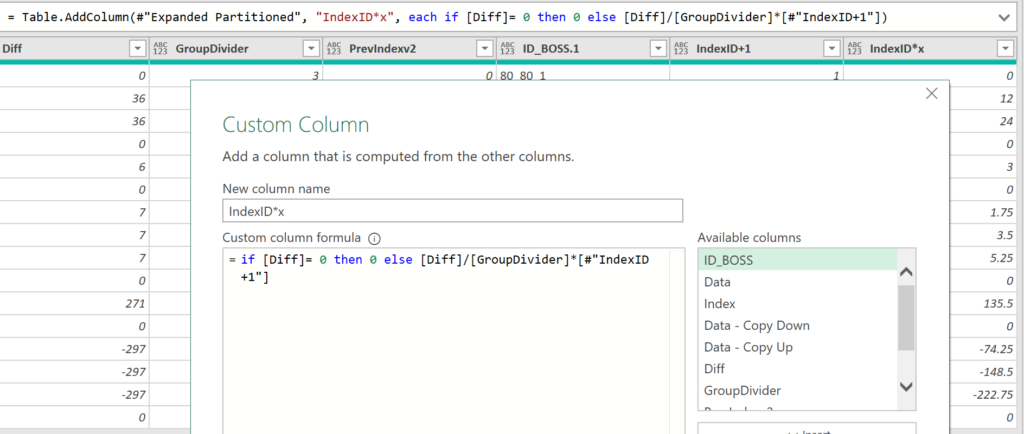
Above we see the Custom Column dialog box where I wrote the formula, the M code that was generated, and the values in column IndexID+1.
Add Column: Table.AddColumn (1 last time!)
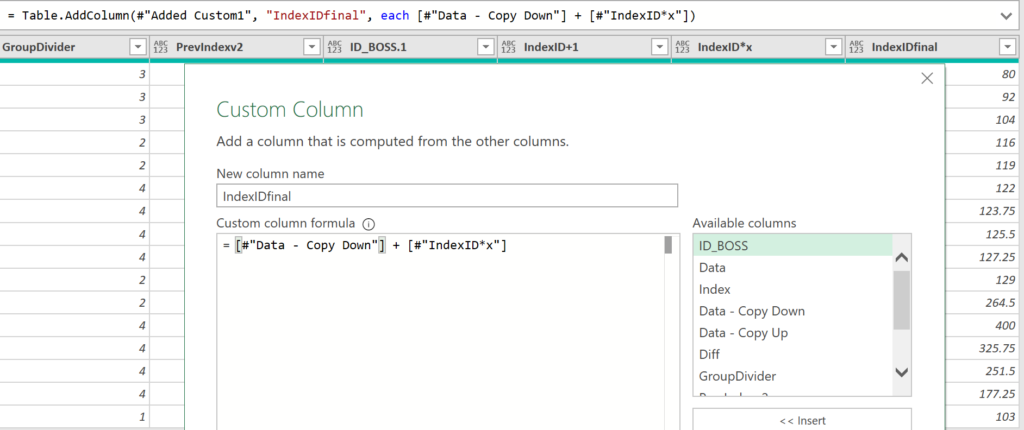
I kept columns IndexID*x and IndexIDfinal as two separate steps. Easier to audit.
Finally, I removed columns and exported to a table in the data model!
Full M code query5 Merge2:
let
//MERGE PREVIOUS 2 QUERIES TO GET THE SUPER KEY :)
Source = Table.NestedJoin(Merge1, {"ID"}, Merge1GroupBy, {"ID"}, "Merge1GroupBy", JoinKind.LeftOuter),
#"Expanded Merge1GroupBy" = Table.ExpandTableColumn(Source, "Merge1GroupBy", {"ID_BOSS"}, {"ID_BOSS"}),
#"Grouped Rows" = Table.Group(#"Expanded Merge1GroupBy", {"ID_BOSS"}, {{"ID+1", each _, type table [Data=nullable number, Index=number, #"Data - Copy Down"=nullable number, #"Data - Copy Up"=nullable number, Diff=number, GroupDivider=number, PrevIndexv2=number, ID=text, ID_BOSS=text]}}),
#"Added Custom" = Table.AddColumn(#"Grouped Rows", "Partitioned", each Table.AddIndexColumn([#"ID+1"], "IndexID+1", 1, 1)),
#"Removed Columns" = Table.RemoveColumns(#"Added Custom",{"ID+1"}),
#"Expanded Partitioned" = Table.ExpandTableColumn(#"Removed Columns", "Partitioned", {"Data", "Index", "Data - Copy Down", "Data - Copy Up", "Diff", "GroupDivider", "PrevIndexv2", "ID_BOSS", "IndexID+1"}, {"Data", "Index", "Data - Copy Down", "Data - Copy Up", "Diff", "GroupDivider", "PrevIndexv2", "ID_BOSS.1", "IndexID+1"}),
#"Added Custom1" = Table.AddColumn(#"Expanded Partitioned", "IndexID*x", each if [Diff]= 0 then 0 else [Diff]/[GroupDivider]*[#"IndexID+1"]),
#"Added Custom2" = Table.AddColumn(#"Added Custom1", "IndexIDfinal", each [#"Data - Copy Down"] + [#"IndexID*x"]),
#"Removed Other Columns" = Table.SelectColumns(#"Added Custom2",{"Data", "IndexIDfinal"})
in
#"Removed Other Columns"
Recap
This was painful. I’m sure there’s a better way to solve it but I did it! Do you have a better solution? Please share!
I learned so many things working my way through this solution. So frustrating but it was incredible practice. If we don’t build things we won’t learn. Theory without practice isn’t worth much.